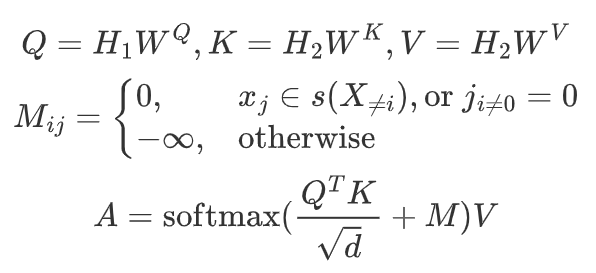- 两个不同的masked input:encoder用其中一个生成embedding;decoder利用embedding和另一个去预测掩码内容
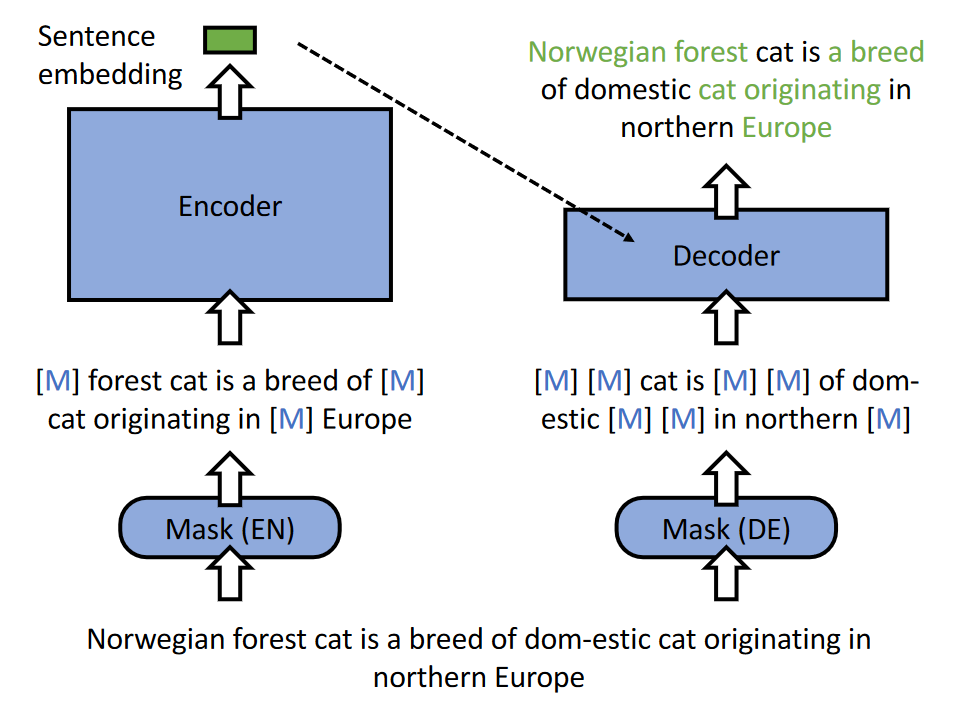
- 不对称的模型结构:encoder用完整的bert,decoder只用一个非常简单的模型,比如一层的transformer(逼迫encoder去编码全面的语义信息)
- 不对称的掩码率:encoder使用比传统MLM略高但适中的掩码率15-30%,decoder掩码率为50-70%
简单的decoder结构+解码时非常高的掩码率 使得重构质量依赖于encoder输出的embedding质量。
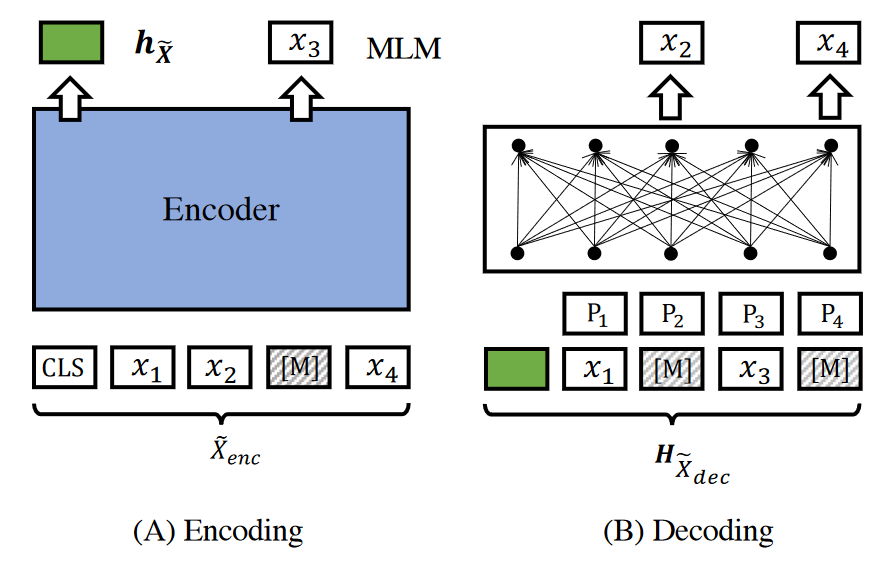
增强解码:对于一个句子,只随机重构一部分token的效率还是不高,可以对一个句子中的每个token都进行重构
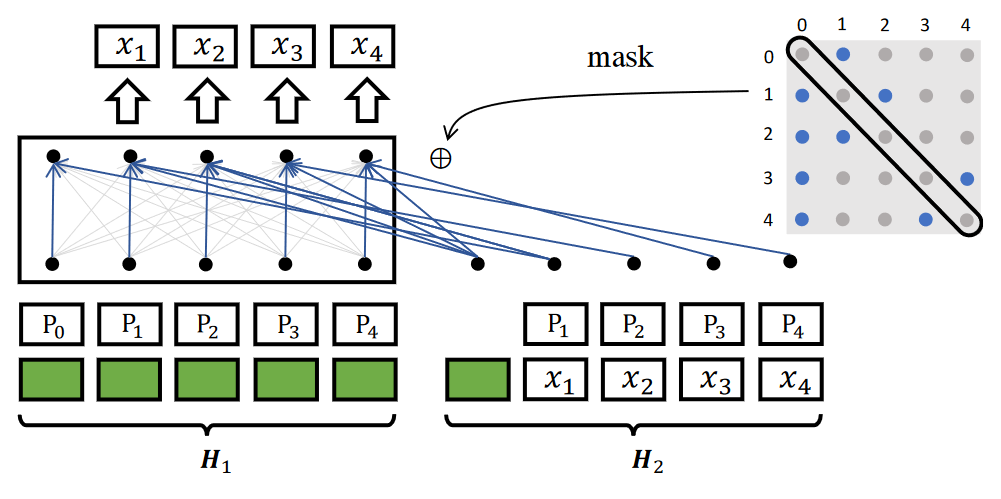
通过attention mask M∈R^{L*L} 限制句子的可见范围,对角线全mask(预测自身时当然不能看到自身),第一个token除了第一个句子以外都不mask(应该是防止整个句子全被mask的情况),其他部分随机采样