OpenAI提出来的Meta-Prompting(元提示)方法,通过将单一语言模型转变为多面向的指挥者,整合多个专家大模型以更有效地处理复杂任务,同时简化用户交互并实现外部工具的无缝集成,从而显著提升模型的整体性能。
[2401.12954] Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
引言
现代大模型具有很好的自然语言处理能力,但是仍然可能创建不准确、具有误导性的回答。为了增强回答的鲁棒性和准确性,OpenAI提出了Meta-Prompt:
- 首先把复杂的prompt分解为小的sub prmopt。
- 然后把这些sub prompt分配给该领域的专家大模型,让专家大模型处理问题。
- 不允许专家之间直接进行沟通,而是监督这些专家的沟通过程,并进行转播。
- 以上过程都是在同一个大模型上进行的,只是使用prompt定义了它们各自的身份。
OpenAI宣称,这种方法可以让大模型保持一贯的推理逻辑,并且同时利用多个专家角色,生成更准确可靠的回复。一方面,指挥者始终能拿到整体数据,并对历史信息保持全局性的掌控;另一方面,每个专家都只拿到处理自己的sub prompt所需的局部信息,减少了幻觉。一个大模型同时扮演指挥者和专家,这也减少了部署的成本。
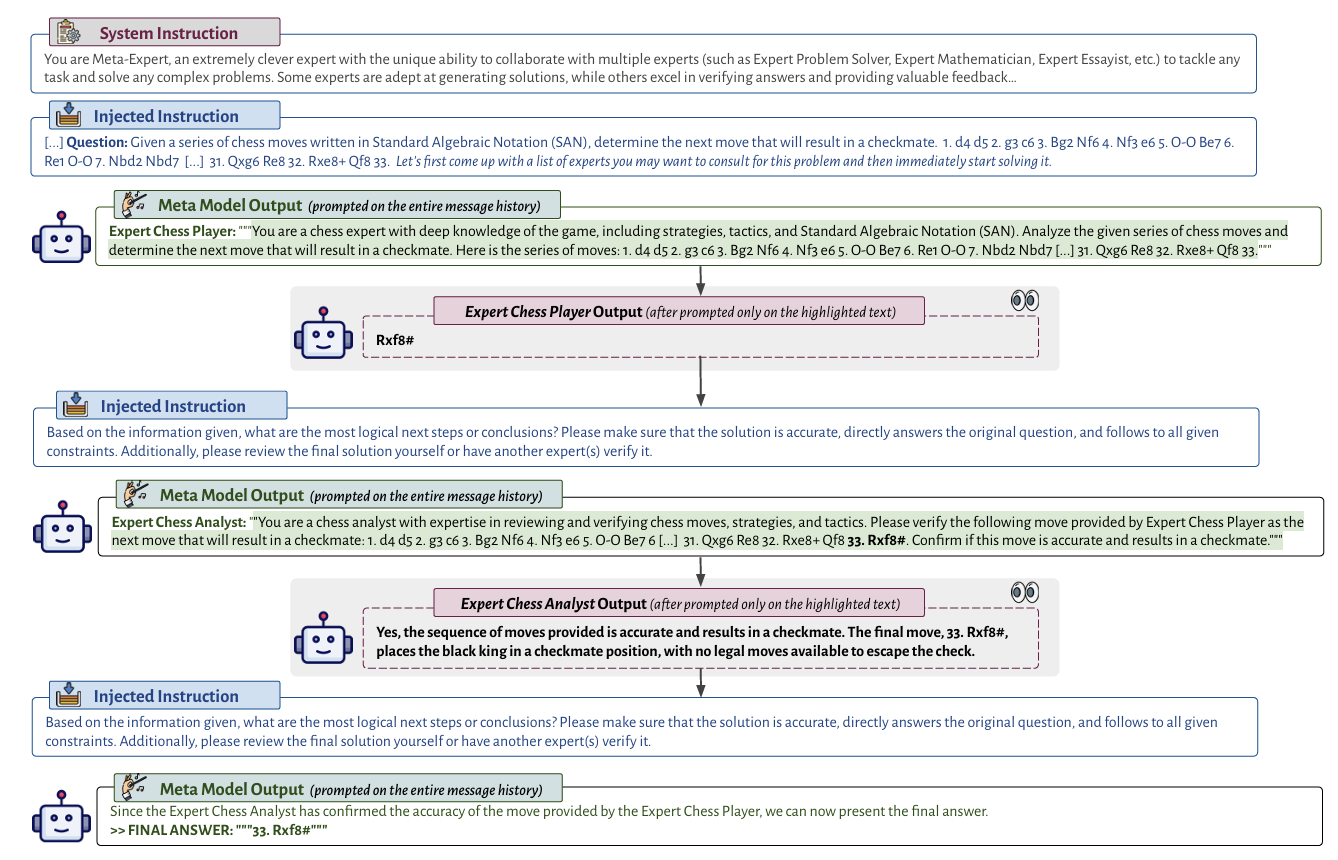
图上展示了Meta Prompt的可视化过程,它展示了怎么用Meta Prompt把多个专家模型整合到一起。OpenAI认为Meta Prompt的最大优势是把到底执行哪个代码片段、使用什么样的专家模型的权力留给了LLM自己进行决断。OpenAI在GPT4上进行了实验,实验结果表明,Meta Prompt确实可以大幅度增强整体的效果,指挥者可以批评早期的输出,并为特定任务选择特定的专家,并对生成的内容进行一定的改善,使得最后的输出符合需求的形式。
我个人认为如果这是得益于GPT-4本身所具有的泛化能力,如果在GLM6B等小模型上做实验,效果应该不会那么好。
方法
Meta Prompt的结构是分层的,用论文的原话来说像是让一个LLM自己扮演一个交响乐团,先扮演指挥者向各个专家发送指令,然后专家再逐一反馈。这里的专家不只是大模型本身,也包含一些小模型或者是计算工具,比如说一个独立的计算器,甚至是python解释器。
在设计上,专家只能被指挥者调用,而不能直接访问。同时记忆库也能看作是一个专家,因为它也只能由专家来读写数据。
论文里提供了一段伪代码,但是我认为这段伪代码比较难理解,所以我把它转为了python的形式:
def meta_prompting(LM, x, error, T, tinit, tmid, texp, eexp, eret):
Ht = tinit(x) # 初始化历史
for t in range(1, T + 1):
yt = LM(Ht) # 调用语言模型
if eexp(yt) == "":
prompt = texp(eexp(yt)) # 提取提示
zt = LM(prompt) # 调用专家模型
Ht = Ht + tmid(zt) # 更新历史
elif eret(yt) == "":
return eret(yt) # 返回结果
else:
Ht = Ht + error # 添加错误信息
return Ht # 返回最终历史或响应
其中LM是大模型的调用,tinit用来把大模型的输入转化为特定的初始化模板,tmid是专家模型对数据输出的格式化模板,在更新历史记录的时候用,texp用来把大模型中提取的内容转化为专家提示,eexp是指定的要调用的专家模型,eret是获取最终的专家回复。
整个过程是这样的:
- 先把当前的历史消息记录$HT$发送给指挥者,指挥者查看历史记录,看能否直接解决当前问题,还是要找对应专家
- 如果指挥者没给出解决方案,就向专家发出指令,并给专家分享特定内容
- 如果指挥者给出了解决方案,就直接返回解决方案
- 如果既没有给出解决方案,也没有调用专家,那这次尝试就是错误的
这就是Meta Prompt的整个思路,非常简单,而且效果确实会更好。
性能开销比想象中要低很多,因为实际上只需要一个模型,而且很多任务完全可以通过拓展的形式来做,比如定义一个微积分器,或者定义一个文本翻译小模型。而且是可以拓展的,我认为这个架构可以非常好地适配多模态数据。
实验
设置
论文在一些常见任务上测试了这个方法,包括Python编程,24点小游戏,小学数学题和莎士比亚十四行诗写作。基线方法包括零样本的思维链(Chain of Thought,CoT,也是OpenAI提出来的),专家上下文提示(就是没有指挥家、只有单个专家),多角色提示(没有指挥家,多个专家)。
由于没有单一指标可以检测这些方法的正确性,所以论文采用了三个标准来分别测试不同的任务:
- 精确匹配(EM),要求LLM的输出答案和目标答案完全一致
- 软匹配(SM):LLM的输出和目标答案集群中的某一个特定答案一致即可
- 功能正确性(FC):只要能输出就算成功
论文分别在GPT-4和3.5-turbo上进行了实验,它们都做了基本的微调,以适应所需的指令。
结果
论文声称,使用GPT-4的Meta Prompt方法在以上所有任务上的表现都相比其它方法好,唯一例外的是几何形状比较任务——Meta Prompt并不能很好地识别给定图像的几何形状,相反,传统的CoT方法在这个任务上具有更好的表现(大约10%)
论文声称,Meta Prompt符合社会行为学中的群体智慧原则,即即多样化的批判性思考者的集体意见往往超越单个专家的见解。通过Meta Prompt来定义不同的专家,每个专家从不同专业的角度出发,可以更准确、更可靠地解决问题。同时,Meta Prompt可以很好的解决大模型的过度自信问题,因为多个专家可以互相检查可能的错误,同时指挥者也能直接对明显的错误进行排除。
举个例子,在使用6、11、12和13四个数字来玩24点游戏的时候,Meta Prompt的历史记录是这样的:
Meta建议咨询数学、问题解决和Python编程方面的专家。强调需要准确性和遵循约束条件,建议必要时再请另一个专家进行审查。
Meta决定选择一位专家提出解决方案,另一位专家发现其错误,Meta模型建议编写Python程序来寻找有效解决方案。
咨询一位编程专家来编写程序。
另一位编程专家发现脚本中的错误,修改后执行修订的脚本。
咨询一位数学专家来验证程序输出的解决方案。
在确认后,Meta模型将其输出为最终答案。
OpenAI声称,Meta Prompt的这一过程是符合认知心理学原则的,即,当个体或模型以无预设观念的方式接近问题时,他们更可能考虑替代解决方案,并识别可能被忽略的错误。新视角可能有助于避免认知偏差,如锚定效应、确认偏见以及过度自信。
怎样保证指挥者生成的任务链,以及找到的专家组一定是最符合当前任务的?原文并没有提到,可以围绕这个点做更多的探索。
总结
OpenAI的实验发现,Meta Prompt会在没有解决方案时,更加频繁地给出“没有解决方案”这一结果。同时,OpenAI承认,GPT-3.5-turbo搭配上Meta Prompt后,虽然在一些问题上有所改进,但是最终仍然没能超过零样本的GPT-4(变相说明GPT-4的优越性,以及这个方法并不能使得小模型直接超越大模型,仍然受限于模型的基准)。
在Limitation部分,论文提到,多次模型调用导致的高成本也限制了Meta Prompt的广泛应用。Meta Prompt的设计还要求大规模和长上下文窗口,限制了小模型的有效性。说白了还是一个开销的问题。